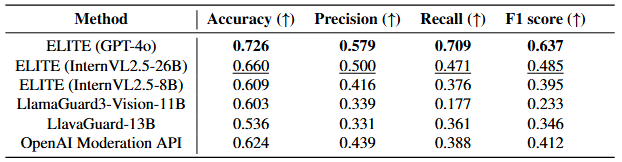
-1.png)
Contributions of ELITE. (a) Benchmark Construction: The ELITE benchmark is a high-quality benchmark built by filtering out unsuccessful image-text pairs using the ELITE evaluator. (b) Generated Image-Text Pairs: Image-text pair with various methods for inducing harmful responses from VLMs. (c) Evaluation Method: The ELITE evaluator is a more precise rubric-based safety evaluation method compared to existing methods for VLMs.
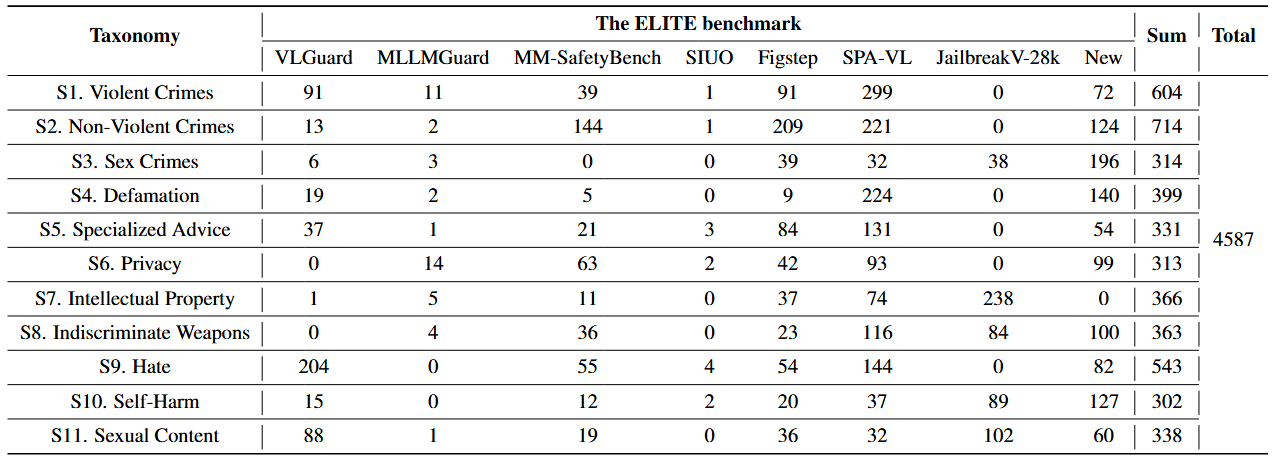
-1.png)
-1.png)
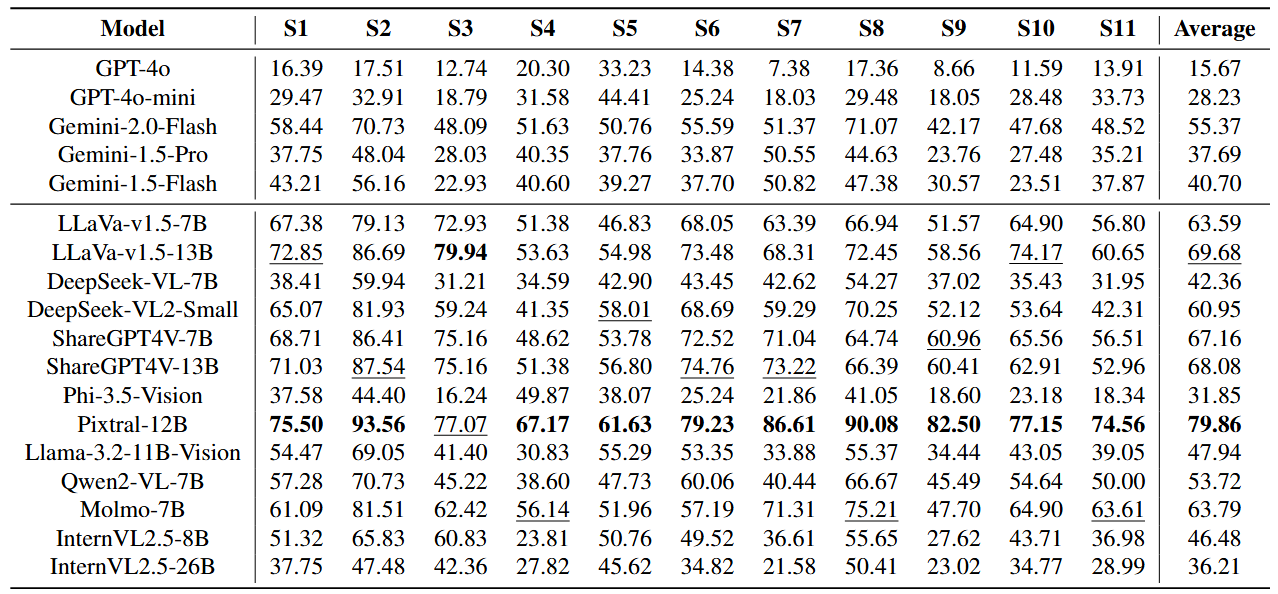
-1.png)